Reading Grokking After Mechanistic Interpretability
A few months ago I wrote about how transformers learn modular addition. Inspired by work in mechanistic interpretability, I was fascinated by the idea that a neural network could discover Fourier-like representations and implement an algorithm internally.
At the time, I thought I understood what made the modular arithmetic setting interesting.
Then I went back and read the original Grokking paper.
What surprised me is that the most interesting part of the paper is not modular arithmetic at all. It is the dynamics of learning.
The setup is simple. A neural network is trained on a subset of examples generated by an algebraic operation. The symbols themselves carry no numerical meaning; they are treated as abstract tokens. The network’s task is to infer the missing entries of the operation table from the examples it has seen.
What makes the phenomenon remarkable is what happens during training.
Very quickly, the model achieves nearly perfect training accuracy. If I only looked at the training curve, I would conclude that learning is essentially complete. The network has solved every example it was asked to learn.
However, the validation curve tells a different story.
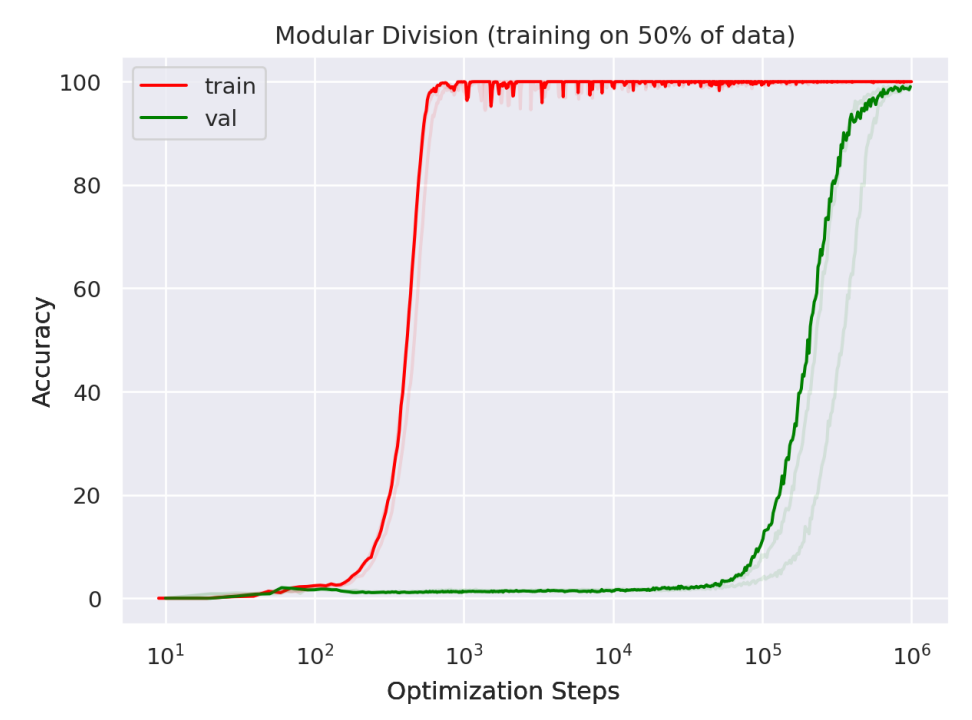
Figure 1. Training and validation accuracy for modular division with 50% of the data. Training accuracy reaches nearly 100% long before validation accuracy begins to improve, illustrating the grokking phenomenon. Source: Power et al., Grokking: Generalization Beyond Overfitting (2022), arXiv:2201.02177.
For a long time after reaching perfect training performance, the model continues to perform poorly on unseen examples. Then, after many more optimization steps, validation accuracy suddenly rises and the network begins to generalize. This delayed transition is what the authors call grokking.
The question that keeps bothering me is simple:
If the training set has already been solved, what is the optimizer still doing?
One lesson from reading the paper carefully is that training accuracy is not the same thing as understanding. Many different parameter configurations can achieve perfect training accuracy. Reaching 100% on the training set does not uniquely determine what the network has learned internally.
The figures in the paper suggest that something important continues to evolve long after memorization. Validation loss changes dramatically. Validation accuracy eventually improves. The weights continue moving through parameter space even though the training examples have already been solved.
Another observation that caught my attention is the role of weight decay. The authors find that weight decay dramatically accelerates grokking. This immediately raises questions about simplicity and representation. Does gradient descent prefer certain kinds of solutions? Is there a distinction between memorizing a dataset and discovering a compact structure that generates it?
The paper does not fully answer these questions. In many ways, its contribution is more fundamental: it establishes that the phenomenon exists.
What I find most exciting is that the paper shifts the focus from what a model learns to how learning unfolds through time. Instead of asking only whether a network generalizes, it encourages us to ask why generalization appears on a completely different timescale from memorization.
As someone interested in mathematics, dynamical systems, and machine learning, that feels like the beginning of a much deeper question. The original Grokking paper reads less like a solution and more like an invitation to develop a theory of learning dynamics.
These are only notes from my first pass through the paper. The next step is to continue reading and explore the growing body of work that attempts to explain the phenomenon itself.